Multi Region Active-Passive DR
Introduction
Service or application availability is becoming more unpredictable with time, whether it is due to natural disaster, human error, hardware failure or minor disruptions due to software failure. This results in huge monetary loss, data loss and bad customer experience. All these factors highlight the significance of having a proper, tested Disaster Recovery environment.
At Integra Technologies, a certified Well-Architected Program Member, we always strive to follow AWS best practices and principles. Building a secure, high-performance, resilient, highly available and efficient infrastructure for applications may seem like a complex task, however, with the flexibility and elasticity of AWS Cloud, it has become relatively easy and simple.
Designing a Disaster Recovery for a workload can be an interesting challenge. It needs a good understanding of the primary infrastructure so that a solution which is reliable, secure, cost effective, easy to deploy and manage in times of disaster can be designed for the DR.
With the plethora of services available from AWS, designing a DR solution is far easier than it used to with legacy systems.
Requirement and Design
Many of the familiar AWS services were being used in the production environment, including EC2, S3, RDS, ALB, and deployment tools like CodePipeline and CodeDeploy. The current infrastructure was designed for high-availability, with EC2 instances being deployed across multiple Availability Zones (AZ). The MySQL RDS is also deployed with Multi-AZ selected.
Code and application updates are pushed using CI/CD services such as CodeDeploy, CodeCommit. These services are regional services – i.e., they are localized within each AWS region.
The existing production environment is shown below.

The architecture is highly available within a region. Though it is unlikely that a whole AWS region may become unavailable, there could be situations where the location from which users connect to the infrastructure could have telecommunication access disrupted to the region where the production infrastructure is hosted. In any case, local compliance requirements specified that a DR infrastructure had to be setup which is not geographically proximate to the production infrastructure.
This led us to opt for a Multi-Region Warm-Standby DR solution. Service features from AWS helped in simplifying the effort required to build such an infrastructure. Some of them were:
- Amazon Aurora with MySQL compatibility offers cross-region replicas, this is asynchronous replication that provides us with the ability to have replicas in different regions.
- Creating EC2 instances in DR region with AMI sharing.
- Code from a single repository can be deployed through multiple pipelines across different regions. On deployment the servers will be up to date with the last commit.
- Amazon S3 offers cross-region replication of objects in a bucket.
- Amazon Route53 failover record type provides us with the ability to failover from a primary location to a secondary based on different health checks.
How it was built
Amazon Aurora MySQL Compatible Edition (Aurora MySQL) Cross Region Replication
For most workloads, the database is the single most important part of the application. The integrity of the application and customer experience depends on how well the database performs and it is important to always have a consistent database state.
Aurora MySQL provides us with the ability to launch read replicas in different regions. This was used to launch a read replica in the DR region. The replication is done by using Binary Log feature (binlog). Cross-region replication for Aurora MySQL uses MySQL binary replication to replay changes on the cross-Region read replica DB cluster. It is preferable that the DB instances in the primary and secondary regions are of the same instance size. This will help in reducing replication lag.
Amazon EC2 Instances
Once Aurora MySQL is up and running, we need to start the application EC2 instances. The prebaked AMI’s from the primary region was shared to the secondary (DR) region. After EC2 instances were launched from these AMI’s, code from DR branch is deployed using CI/CD with AWS CodePipeline.

Deployment Pipelines
We started by building a separate pipeline for the DR region. We could have used CodePipeline Cross-Region Actions to deploy the code in the DR region with the production pipeline. However,we chose not to use this, since, in case of the region not being available or a service unavailability in the region, any pipeline triggered in the primary region would not succeed. Another important advantage of this strategy is that there it helps us in avoiding a single point of failure. Therefore, a separate pipeline in the DR region was setup and the code for DR branch is pushed to different S3 versioned buckets in both regions. Using CloudWatch events, CodeDeploy deploys this code using either a Blue-Green or an in-place deployment strategy.
S3 Replication
Amazon S3 is designed to provide highly durable storage for mission-critical workloads. S3 offers an SLA of 99.99% for the availability of objects but as best practice, we decided to create the replica of S3 buckets as well. AWS S3 Buckets can easily be replicated to other regions using Cross Region Replication feature. As new objects are being uploaded to the primary bucket, they are continuously replicated to the bucket in the DR region. In case of a disaster, site assets will be served from the secondary bucket. This ensures that we have a resilient and a reliable solution.
Designing Failover Strategy and Conditions for Failover
The conditions for failover must be well thought out. The production site should not failover at the slightest disruption to the primary infrastructure, as this will cause more problems than what we set out to solve – use the DR in case of complete loss of region availability.
Question we asked ourselves were:
- How do we switch from the primary environment to secondary environment?
- How much time would it take to switch to the Secondary Site?
- Do we completely automate the failover or do we need some kind of approval from a human to make sure that an automation error or logic error has not inadvertantly triggered the failover? Or do we failover manually on receipt of a CloudWatch or PagerDuty alarm?
- How would monthly or ad-hoc maintenance with downtime impact the failover?
AWS Route53 offers plenty of rich features. In addition to the normal DNS records, it offers other features as well, for e.g., Route 53 Failover record. This record type is designed for an Active-Passive system where Route53 Failover can determine the results of health checks of the workload using domain endpoint health checks, state of other health checks or CloudWatch alarms status and then decide where to route the requests.

We have used multiple health checks in conjunction to support the failover strategy.
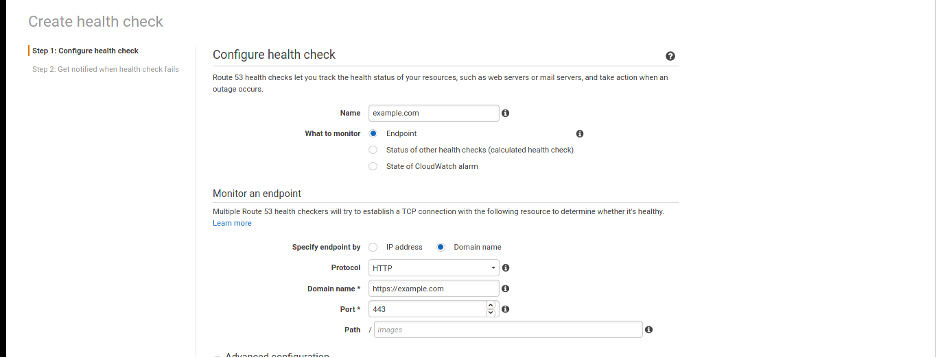
The image above shows an example of an endpoint alarm. This endpoint alarm determines if the primary endpoint example.com is healthy or not. However, it is critical that we do not associate this health check with primary failover record type. Even in case of a momentary non-availability of the primary site, the result of this health check can case Route53 to failover traffic to the Secondary Region.
The main objective of this health check is to inform the operations team about the application or infrastructure’s potential unavailability. Once the health check is unhealthy an alarm is triggered which sends an SNS email notification to the operations teams that the site is down.
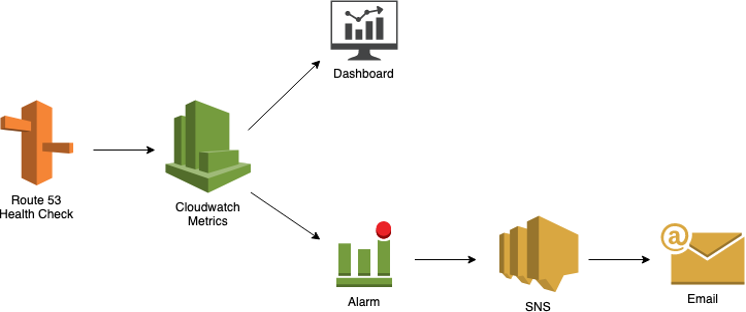
To trigger the actual failover, we need to create a health check based on CloudWatch alarms for the primary failover record. We have to use CloudWatch alarm rather than an endpoint alarm due to the fact that endpoint health checks will only allow a maximum failure threshold of 10, with either a 10 second interval or a 30 second interval, thus giving us a maximum of 300 seconds to decide on the failover.
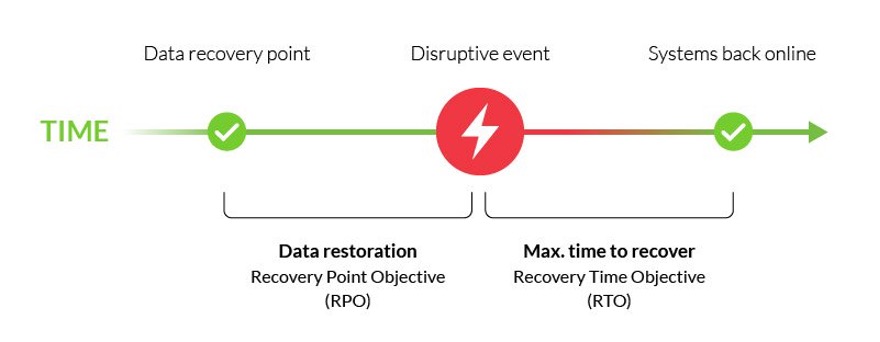
This could lead to unwanted failover in the case of this particular customer as the defined RPO is 30 minutes. To tackle this problem, we created a health check based on CloudWatch alarm with multiple data points. If the website remains unavailable for 30 minutes the state of the alarm changes and causes the failover to the secondary record in the DNS.
Another CloudWatch alarm is generated once the failover is initiated. This alarm is used to trigger a lambda function that modifies the value of the Primary record with the value of DR record. This is done to ensure that in case the primary site becomes available and the health check returns as healthy, traffic is not routed back again to the now available primary, as this will cause data inconsistency.
A failback is performed manually, by creating a replica of the database and restoring the data in the primary region, and then changing the DNS records to as it was initially.